
Réseau de neurone supervisé - Data Set – Dogs vs. Cats
Data Set kaggle

Dogs vs. Cats est un jeu de données constitué de 25000 photos couleur labellisées de format divers (ex : dog.2899.jpg – cat.1137.jpg) et d’un jeu de données de test de 12500 images couleur non labellisées (ex : 2518.jpg).
Index.
Preamble – Préambule.
CNN – MNIST Fashion.
Le réseau CNN était constitué d’un petit Data Set de 60.000 images de Training et 10.000 images de Test en noir et blanc en basse résolution (28 x 28 pixels).
Il était également charger directement en mémoire à partir du site de Tensorflow dans 4 matrices ou tenseurs ndarray de numpy .
Rem : On appelle Matrice un tableau à 2 dimensions, pour 1 dimension on dit Vecteur et pour + de 2 dimensions on dit Tenseurs.
- (train_images) de Shape (60000, 28, 28) – Contenant les images train.
- (train_labels) de Shape (60000) – Contenant les Labels de train_images.
- (test_images) de Shape (10000) – Contenant les images test.
- (test_lables) de Shape (10000) – Contenant les Labels test_images.
CNN – Dogs vs. Cats Kaggle.
Pour le Data Set Dogs vs Cats de Kaggle cela est très différent. Il est constitué d'un Data Set de training unique de 25000 images couleurs labellisées et d’un Data Set non labellisé de test de 12500 images.
- Premièrement il faut downloader sur Kaggle les fichiers et les de-zipper si nécessaire. (814.4 MB)
- Les dimensions des images sont variables. (X ?, Y ?).
- Il n’est pas possible (sauf exception d’avoir énormément de Ram) de charger les fichiers en Ram.
- On peut estimer qu’il faudrait environ12 gigaoctet de RAM. Soit 25 000 images de Shape de moyenne de (200 X 200 X 3) pixels chacune, soit une valeur en pixels 3.000.000.000 de 32-bit. Il faut redimensionner les images avant traitement (soit a priori dans des folders annexes soit à la volée).
- Comme la structure des noms des fichiers du Data Set Train est structuré comme suit (0.jpg, ***, cat.124999.jpg, dog.0.jpg, dog.124999.jpg,***) il sera également nécessaire avant toute opération d’extraire les labels.
CNN – Marche suivre classique.
Apres avoir extrait les labels du Data Set train soit dans un (fichier, matrice ou DataFrame) et avant de créer un modèle, de le compiler et de l’entrainer (Fit model), il faut d’abord :
- Exécuter un Resize des images.
- Exécuter un Suffle – mélanger les données.
- Créer un Data Set de validation – Split généralement de 20%.
- Normaliser les images.
- Exécuter un Reshape pour la Convolution.
- Exécuter un one-hot-encoding pour les Classes.
- Créer Les Batchs.
Tout ça est un peu fastidieux et c’est là qu’intervient les fonctions de haut niveau de l’API de Keras. La fonction ImageDataGenerator de Keras va nous permettre de réaliser la quasi-totalité des opérations décrite ci-dessus.
Keras ImageDataGenerator.
Image Data Augmentation With ImageDataGenerator.
Un paramètre important du Deepelarning supervisé de classification d’images concerne la qualité du Data Set. En effet si le les images sont trop ressemblante, le système commercera à apprendre par cœur. C’est le problème d’Overfiting.
Pour illustrer mes propos, imaginons que dans toutes les images Dogs on retrouve par exemple une chaise au même endroit. Après le training, quand le système détectera une chaise, il déclarera que cette image est automatiquement un Dog.
ImageDataGenerator, permet en plus des fonctionnalités ci-dessus bien d’autres opérations sur les images avant traitement et permettre ainsi la variabilité de celles-ci.
- Horizontal and Vertical Shift Augmentation.
- Horizontal and Vertical Flip Augmentation.
- Random Rotation Augmentation.
- Random Brightness Augmentation.
- Random Zoom Augmentation.
L’intérêt du Data Augmentation est de créer artificiellement à partir d’une image un Bach contenant une suite d’images légèrement modifiées. Le résultat est une augmentation artificielle du nombre d’images du Data Set ainsi qu’une amélioration de celui-ci.
A partir de l’mage suivante, nous allons mettre en évidence la plupart des paramètres de cette Class.

Create an instance of the ImageDataGenerator.
Ex : datagen = ImageDataGenerator()
Après avoir créé l’instance datagen, il est nécessaire de créer un iterator pour le Dataset, c’est la fonction flow() . Cette fonction renvoie un Bach d’images augmentées pour chaque itération. En résumé cette fonction charge les données en fonction des paramètres de celle-ci (voir Doc).
- flow()
- flow_from_directory()
- flow_from_dataframe.()
Fonction - flow().
X est un ndarray ou un tuple contenant les images.
Y contient les Labels.
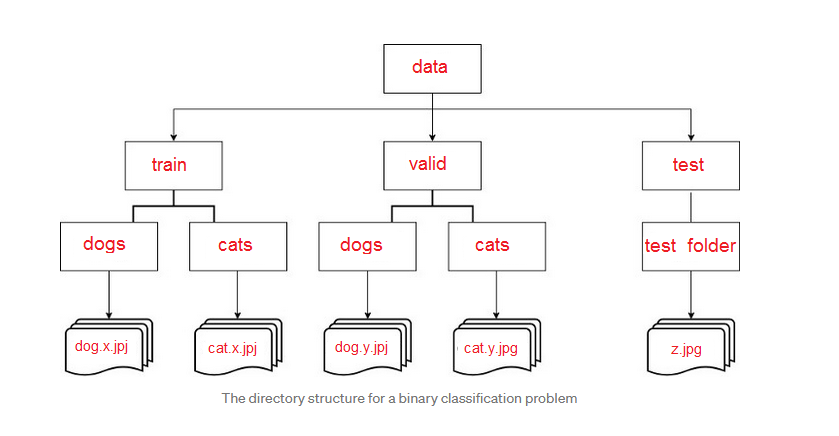
Fonction - flow_from_directory().
directory contient le Path vers le Dada Set ex : (./data/train)
Ici l’iterator est créé à partir du Data Set localisé sur le disque dur mais la structure des données doit respecter un schéma spécifique.
Fonction - flow_from_dataframe.().
- dataframe est une structure Pandas.
- directory contient le Path sur le directory data.
- x_col contient le/les noms des fichiers images.
- y_col la/les différentes classes.
Exemple : DataFrame
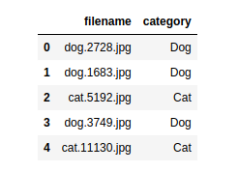
J’avoue que j’ai une préférence pour la structure DataFrame de Pandas et jutiliserai cette strucure dans la suite du développement de cet exposé.
Pandas.
Pandas est un tableur avec de nombreuse fonctions. Il est très utilise pour préparer/ou créer un Data Set .
Mise en œuvre de Keras ImageDataGenerator.
Tratement de Base.
- Rescale.
- samplewise_center.
- samplewise_std_normalization.
Data Augmentation.
- Horizontal and Vertical Shift Augmentation
- Horizontal and Vertical Flip Augmentation
- Random Rotation Augmentation
- Random Brightness Augmentation
- Random Zoom Augmentation
Petit rappel.
Au départ le système n’est pas capable de faire cette opération et génère une erreur ou discordance. L’apprentissage, consiste à minimiser l’erreur (Cross Entropy) par un Optimizer. L’Optimizer minimise pas-à-pas (Learning Rate) l’erreur de Cross Entropy par un algorithme de descente de gradient. En résumé, on tente de faire converger la fonction (voir Théorie Mathématique).
En conclusion, toutes les opérations permettant d’adapter les données en vue d’un traitement algorithmique par computer est absolument nécessaire.
Rescale – Redimmensionner.
Comme dit le dicton, on ne compare pas des pommes avec des poires !
Les images Input (RGB ou RGBA) suivant le triangle de Newton, sont constituées de 3 ou 4 couches.
Les données d’une couche varient de (0 – 255).
La première opération va donc consister à redimensionner les données entre (0.0 – 1.0) par une division de 255.
Le Rescale effectue en plus, par défaut, un redimensionnement de l’image (255 x 255). C’est déjà une Normalisation.
Samplewise Center.
Paramètre : samplewise_center = True or False
Modifie les données de l’image afin d’obtenir une moyenne nulle.
Random Horizontal Shift Augmentation.
Paramètre : width_shift_range
Il permet de déplacer tous les pixels de l’image horizontalement par rapport à un range donné tout en conservant les dimensions de l’image.
Si le range est float, le déplacement est défini en % - ex : [0.5, 0.5].
Si le range est int, le déplacement est défini en nombre de pixels – ex : [100, 100].
Random Vertical Shift Augmentation.
Paramètre : height_shit_range
Identique au shift horizontal, mais le déplacement se fait verticalement.
Random Horizontal Flip Augmentation.
Paramètre : horizontal_flip = True or False
Retournement de l’image horizontalement.
Random Vertical Flip Augmentation.
Paramètre : vertical_flip = True or False
Retournement vertical de l’image.
Random Rotation Augmentation.
Paramètre : rotaion_range en Degré de 0 – 360
Random Brightness Augmentation.
Paramètre: brightness_range
Valeur des paramètres en float ce qui donne un % d’assombrissement ou d’éclaircissement.
Varie de 1.0 (pas de changement) à 0.0.
Ex : brightness_range = [0.2, 1.0 ] va assombrir de manière aléatoire l’image entre 1.0 (pas de changement) à 0.2 soit 20 %
Random Zoom Augmentation.
Paramètre : zoom_range
Valeur float, [lower, upper] donne un % de variation.
Ex : zoom_range = [0.5, 1.0]
Vu que les données ont été modifiées en vue du training, imshow de matplotlib n’affiche qu’une représentation des données.
Références :
Create Model Type VGG16 - Training -Evaluate and Predict.
Dans ce qui va suivre, nous allons tester plusieurs modèles CNN de classification d’images. Un modèle basé sur l’article du site (https://data-flair.training/), un modèle de type VGG16 basé sur l’article du site (https://towardsdatascience.com/) , nous apprendrons à utiliser le modèle VGG16 Pre-Trained (Pré-formé) de l’API de Keras (https://keras.io/) et je finirai ce chapitre par une méthode qui n’engage que moi pour faciliter la création d’un modèle CNN de classifications d’images de base afin d’obtenir des résultats satisfaisants.
Rappel sur le Modèle VGG16.
VGG16 est un modèle de réseau de neurones convolutif proposé par K. Simonyan et A. Zisserman de l'Université d'Oxford dans le document «Very Deep Convolutional Networks for Large-Scale Image Recognition». Le modèle atteint 92,7% de précision de test, top-5 dans ImageNet,qui est un ensemble de données de plus de 14 millions d'images appartenant à 1000 classes. VGG16 a été formé pendant des semaines et utilisait des GPU NVIDIA Titan Black.
Préparation du Data Set Dogs vs. Cats de Kaggle.
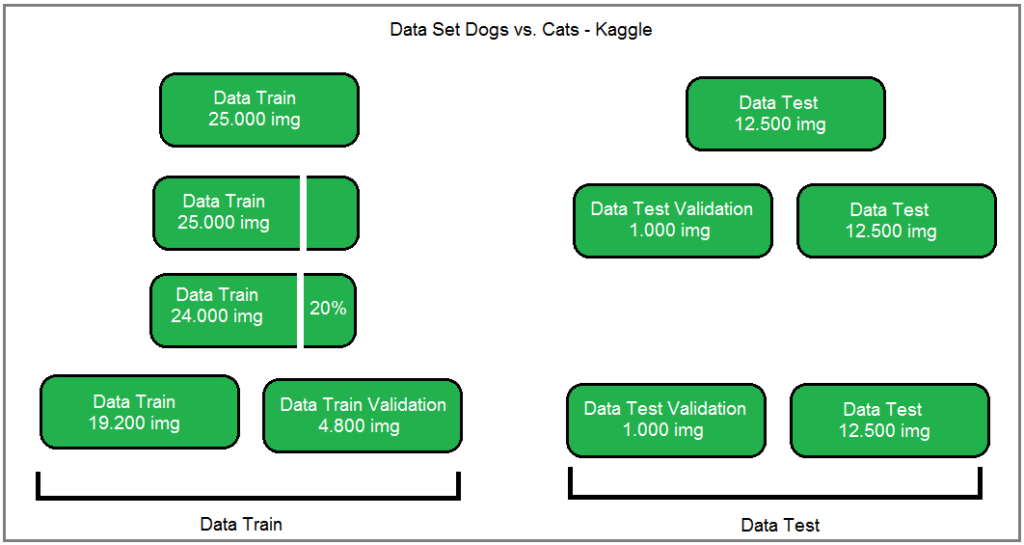
- Data Set Dogs vs. Cats de Kaggle, soit 25.000 images.
- Data Test Validation, soit 1.000 images. Cette démarche m’est personnelle, elle me servira à réaliser une prédiction en vérification la concordance des labels.
- Data Train Validation, soit 4.800 images. C-à-d 20 % des 24.000 images du Data train résiduel.
- Data Train, soit 19.200 images, soit le Data train résiduel moins les 20 %.
Model From (DataFlair).
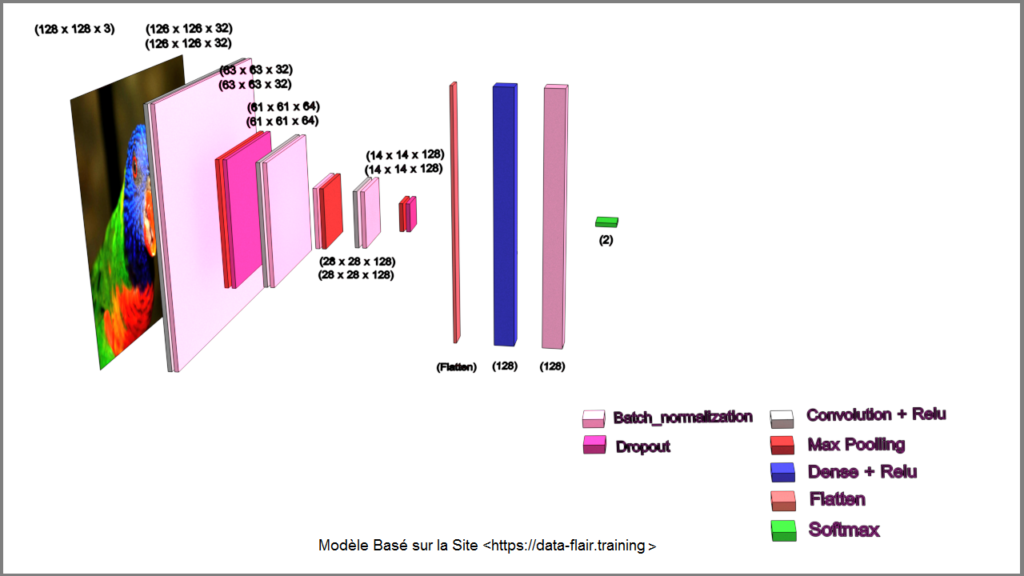
Le modèle proposé sur le site « data-flair.training » est un modèle inspiré du modèle VGG16 et prédit une accuracy de 98.7 % avec l’Optimizer « RMSprop » et un Callback_list_1 (voir listing code). Sauf erreurs de ma part, après un Training de +16h, le résultat est décevant. On obtient une accuracy de seulement 76.04 % et surtout un loss de 49.00 % ??
Un nouveau training basé sur le résultat du training précédant, confirme les mauvaises performances de ce modèle.
- Rem : dans le modèle proposé du site « data-flair.training » bien qu’il prédise un accuracy de 98.7 %, il ne précise pas laquelle (validée ou non), il ne parle pas du Loss et surtout il ne montre aucune courbes.
En conclusions :
- Il ne suffit pas d’ajouter des Layers pour augmenter les performances.
- En fonctions du nombre et du type de Layers, le nombre d’images de training, le nombre de bachts, le nombre Epoch ainsi que le Learning Rate peuvent influencer fortement les performances.
- En l’état de mes connaissances actuelles, je n’ai pas trouvé de règle systématique pour l’élaboration d’un modèle performant. Je préconise de construire le modèle couche par couche et d’évaluer ses performances en fonctions des courbes.
- En résumé, ce modèle reste inexploitable en l’état et il est inutile de poursuivre son investigation.
Model Type VGG16 of Keras (non-adaptative).
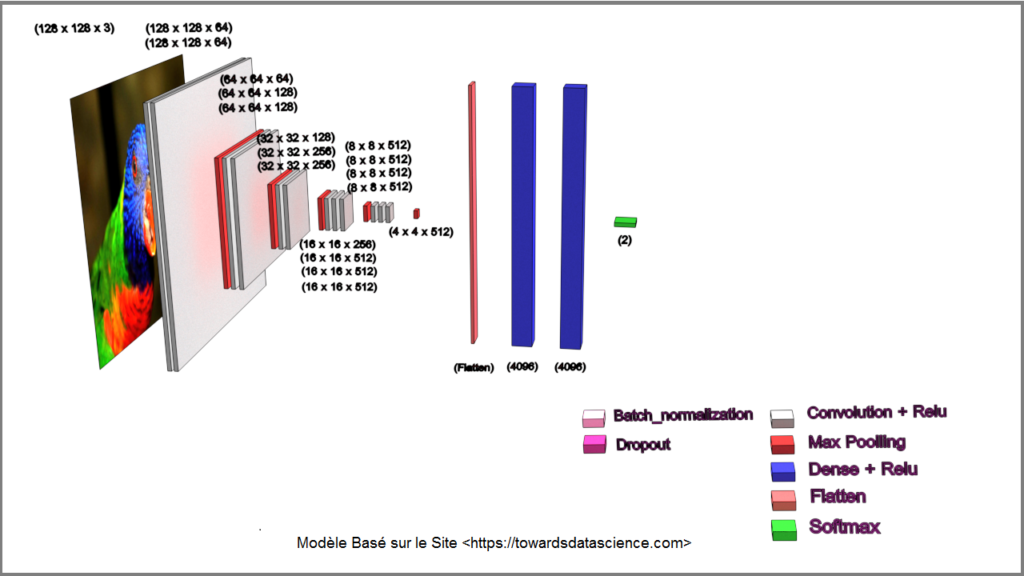
Le modèle proposé sur le site « towarsdsdatascience.com » est un modèle inspiré du modèle VGG16 . Ce modèle est « non-adaptavive ».
je l’ai encodé manuellement, il n’a pas été créé par l’API Keras Applications comme cela sera le cas dans le modèle suivant.
J’ai entrainé de modèle avec l’Optimizer « Adam » un Learning Rate de 0.0001 et un Callback_list_2 (voir listing code).
Après un training de +24h, ce modèle donne toute satisfaction avec une accuracy de 96.83 % - val_accuracy 93.67 % et un loss de 8.21 % - val_loss 16.74 %.
- Ce modèle est tout à fait exploitable.
Model Type VGG16 from API Keras Applications (adaptavive).
Ici nous allons créer une modèle VGG16 à partir de l’API Keras Application.
Cet API propose toute une série de modèle Pre-Trained (Pré-entrainé).
Avant de nous lancer dans la création de ce modèle, nous allons effectuer un rapide survol de cet API.
Dans le modèle qui va suivre je n’utiliserai que le modèle (non entrainé) mais par la suite j’utiliserai d’autres fonctionnalités dans des modèles plus complexe comme par exemple (Model : R-CNN – Region Based Covolution Neural Netwoks ) pour la détections d’objets.
Pre-Trained Models Keras andTransfer Learning.
Bien que Keras Applications met à notre disposition 26 modèles de réseaux, je ne m’attarderai que sur le modèle VGG16 (VGG pour Virtual Goemetry Group spécialisé dans la vision par ordinateur à l’université d’Oxford et 16 pour 16 Layers).
Le modèle VGG16 (Very Deep Convolution Netwokrs for Large-Scale Image Recognition) pour la classification d’images a été entrainé sur plus 1.000.000 d’images et pour 1.000 catégories ou Classes. Le modèle a été optimisé pour des images de dimensions (224 x224).
Il peut en fonctions des paramètres être utilisé de plusieurs manières :
Classifier.
Le Model Pre-Trained est directement utilisé pour classifier une image de classe similaire.
Dans ce cas il est nécessaire de charger les poids du modèle (Weight Initialisation).
Standalone Feature Extractor.
Le Modèle Pre-Trained ou partie de celui-ci est utilisé pour prétraiter l’image et en extraire les caractéristiques pertinentes.
Integrated Feature Extractor.
Le Model Pre-Trainted ou une partie de celui-ci est intégré dans un nouveau modèle.
Les Layers du modèle Pre-Trained ne sont plus actif durant le sont Training.
Mon programme d’exemples met en œuvre :
Method Classifier.
Utilisation du modèle pré-entrainé pour effectuer une prédiction parmi les 1.000 Classes du modèle.
L’image doit d’abord être redimensionnée en (224 x244 x 3) – image couleur.
Lors de la première instanciation il télécharge le modèle et les poids (vgg16_wieghtd_tf_dim_ordering_tf_kernels.h5) dans le répertoire (~/.keras/models/.).
Lors de la première prédiction il charge les Labels (imagenet_class_index.json).
En conclusions, cette méthode peut-être pratique pour classifier rapidement un data set d’images.Les classes sont prédéfinies mais en Anglais.
Method Standalone Feature Extractor.
On utilise une partie de ce modèle pour extraire des données qui seront sauvegardée en fichier plk dans le but de créer un nouveau Data Set qui pourra être utilisé dans un nouveau modèle.
- Le fichier plk (https://docs.python.org/3/library/pickle.html) est un fichier binaire de sérialisation.
Dans le modèle VGG16, on supprime la couche de sortie, ici le Softmax, qui n’a ici aucun intérêt.
Pour me faire une idée plus précise de l’utilisation d’une telle structure, j’ai également analysé le data_batch_1 du Data Set (CIFAR-10) qui est également un fichier plk. On constate qu’un fichier plk peut contenir des données multiples, certes des images mais peut également contenir la sauvegarde d’un modèle entier.
- Data Set (CIFAR-10) http://www.cs.toronto.edu/~kriz/cifar.html
Je me suis également posé la question sur l’utilisation avancée de l’utilisation des fichiers plk. Par exemple dans cet article, on l’utilise dans un modèle complexe pour la création et le training d’un modèle combiné (LSTM Long Short Term Memory – RNN Recurent Neural Network, utilisé comme générateur de phrases, recevant en entrée GloVe word embeddings - vecteurs mondiaux pour la représentation de mots, combiné à une modèle CNN Convolutional Neural Network - VGG16 Pre-trained). Après training, ce modèle sera capable, à partir de l’analyse d’un images fixe ou d’une séquence vidéo de prédire par exemple: (Young girls in pink shirt is walking through the grass, This dog runs through the grass).
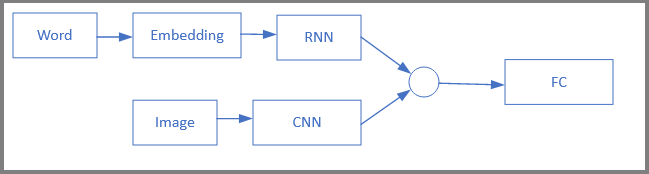
Ce modèle est actuellement trop complexe pour aller plus avant dans sa description mais je vous invite à parcourir cet article pour informations.
- Image Caption using Neural Networks. https://xiangyutang2.github.io/image-captioning/
Les deux modèles VGG16 décrit ci-dessus sont certes intéressant, mais ils ont quelques inconvenants.
Comme on garde soit l’entièreté ou une partie des fonctionnalités du modèle Pre-Trained, celui-ci n’est pas Standalone.
Lors de répétitions de l’exécution du même modèle >5 (par exemple lors de la mise au point), l’API Tensorflow vous envoie un Warning vous stipulant que la définition de vos fonctions ne sont pas optimalisée et que vous devez définir les fonctions en type @Functions (voir doc Tensorflow).

Method Standalone Feature Extractor.
Pour ma part cette méthode est très intéressante car elle permet la création d’un modèle Standalone complétement indépendant tout en gardant une structure optimale du réseau CNN VGG16.
- On remplace la couche Input part nos propres paramètres.
- On désactive les couches intermédiaires.
- On supprime la/les couches de sortie.
- On ajoute nos propres couches de sortie.
Dans mon exemple :
- Une couche d’entrée de dimension (224, 244, 3)
- Deux couches Dense ou Full Connect (Fc) de dimension (4096) avec une activation Relu.
- Une couche de sortie (2 Classes) d’activation Softmax.
Cette méthode est adaptative.
Bien qu’au départ prévue pour une entrée de dimension (224, 244, 3).
Si vous décidez d’une entrée de dimension (128, 128, 3) le modèle adapte automatiquement les dimensions des couches intermédiaires.
Ici se termine le survol de la description de l’utilisation du Modèle VGG16 de Keras. Ce paragraphe est certes un peu fastidieux, mais me semblait nécessaire et utile pour la compréhension lors de l’utilisation d’autre modèle de Keras Applications.
Références :
Create & Training Model Type VGG16 from API Keras Applications (adaptavive).
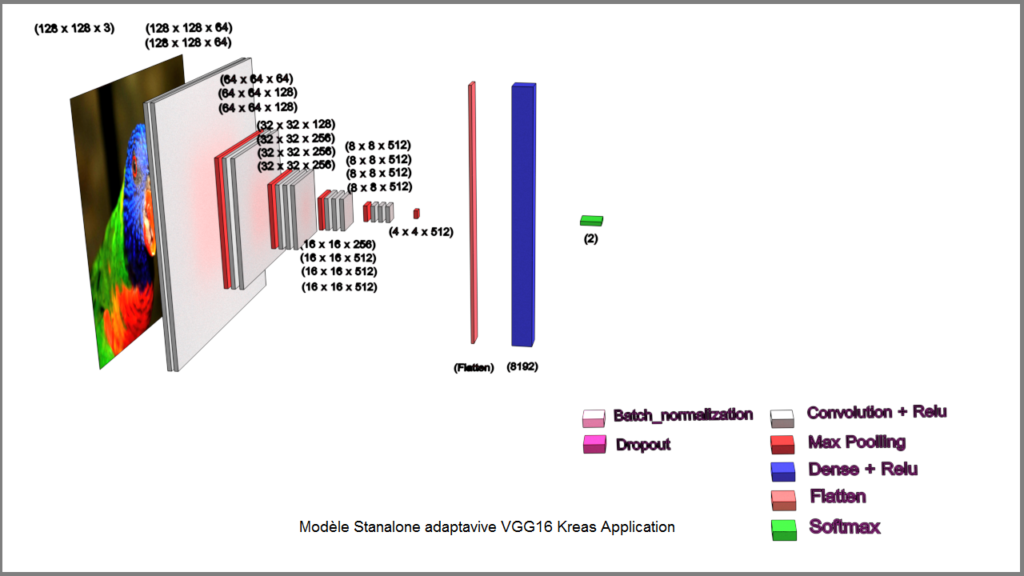
J’ai entrainé de modèle avec l’Optimizer « Adam » un Learning Rate de 0.0001 et un Callback_list_2 (voir listing code).
Après un training de +9h, ce modèle donne toute satisfaction avec une accuracy de 94.78 % - val_accuracy 89.44 % et un loss de 13.19 % - val_loss 24.97 %.
- Ce modèle est tout à fait exploitable.
Method for creating a CNN Model of Performing Image Classifications.
Cette méthode n’engage que moi !
- Utilisation d’un modèle VGG16 Standalone pour avoir une idée cohérente du futur modèle.
- Faire un training couche par couche et regarder sa tendance en utilisant les courbes.
- Une fois que le modèle semble cohérant, tester le training avec d’autres Optimizer.
- Pour terminer essayer d’améliorer la vitesse de training en utilisant des layer (Padding ou Maxpooling et Droptout).
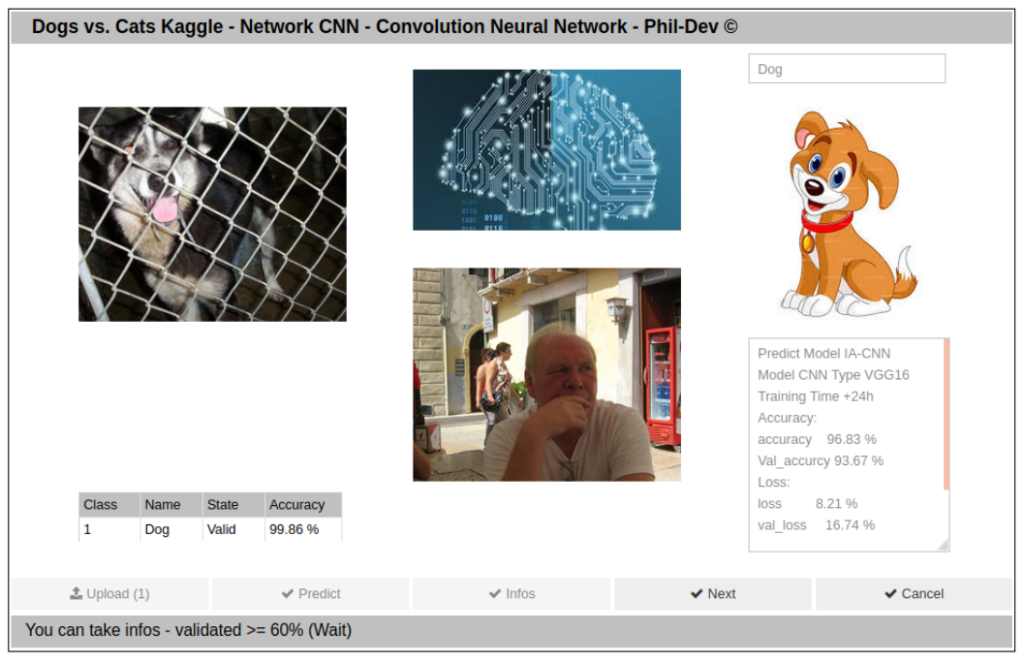
Mise en Production du Modèle CNN Dogs vs. Cats.
Comme précédemment (voir - CNN MNIST Fashion) , j’ai opté pour une application Web par l’utilisation du serveur local Jupyter Notebook en mode Background Appmode et l’API IpyWidgest.
Screen de l’Application.
Limite du Modèle.
La principale limitation est due à la couche de sortie d’activation Sotfmax. Par définition mathématique, l’équation Softmax en peut retourner après prédiction qu’une seule classe et la somme des probabilités de toutes les classes est toujours égale à 1. En résumé Softmax donnera toujours un résultat et si l’entée n’a aucune correspondance aux classes de training.
Vous êtes certain d’obtenir un faux positif.
Conclusions.
Bien que ce modèle soit plus complexe que le précédent (CNN MNIST Fashion) il reste finalement très basique et est incapable de faire une prédiction correcte s’il n’est pas utilisé dans le domaine pour lequel il a été conçu et mise au point. Par exemple, si vous lui donnez en entée une image qui ne contient pas un Chien ou un Chat, le système donnera une prédiction qui sera un faux positif.
Discutions sur l’application Web Jupyter Nootebook Appmode IpyWidgets & Ipsheet.
J’avais constaté qu’aussi bien en exécution Local qu’en Remote Access un ralentissement de l’application après plusieurs prédictions en cascade.
Genèse :
Mon idée de départ était la suivante. Vu que Jupyter Notebook (ipython) est un serveur Local permettant le développement d’application Python, je me suis dit qu’il serai intéressant d’utiliser cette spécification pour visualiser en Remote Access le résultat d’un développement. Cette méthode n’est évidemment pas prévue pour la mise en production dans le monde réel et reste destiné à une utilisation en mode démo. Pour la mise en production d’applications IA, il existe des Hardwares spécifique, des clound et des modules pouvant recevoir des modèles entrainé.
Mais quoi qu’il en soit cela n’explique pas le ralentissement constaté.
Points d’investigations :
Il n’est pas impossible que le serveur Jupyter Notebook soit limité dans ses performances et de plus par l’utilisation simultanée de Tensorflow (rem : j’ai déjà modifié certains paramètres de celui-ci comme par exemple son ( iopub_data_rate_limit). Il exécute son code en mode natif Python c-à-d en mode interprété ligne par ligne.
Tensorflow depuis sa version 2.0 exécute par défaut son code en mode (eager) c-à-d également en mode natif Python interprété. Tensorflow possède un autre mode d’exécution plus rapide le mode (Graph). Dans le mode Graph Tensorflow prépare et charge en mémoire une structure de code (un Graph) avant son exécution (une analogie certes hasardeuse serai une comparaison avec du code compiler). Bien que ce mode est plus rapide et permet une utilisation du modèle même sur une autre plateforme sans utiliser Python, sa mise en œuvre est complexe et je suis loin d’être rassuré sur n’inéquation de l’utilisation de Jupyter notebook avec Tensorflow en mode Graph.
Une solution serai de créer le code directement en Python natif (.py) et trouver une autre solution pour la diffusion en remote access web ou d’investiguer dans PyTorch (un environnement similaire à Tensorflow et en pleine évolution dans le monde scientifique).
Possible problème de saturation lors de l’utilisation en boucle IpyWidgets et Jupyter Notebook. IpyWidgets est une API permettant le développement d’éléments Web dans Jupyter notebook.
Idem pour l’API Ipsheet utilisé comme tableur Web dans Jupyter Notebook.
Résolution du problème (voir Code).
- Test de validation Tensorflow mode eager & Jupyter Notebook – (Test Ok).
- Test IpyWidgets – chargement des images & Jupyter Notebook – (Test OK).
- Test routine de validation des images – (Test OK).
- Test instantiation Ipysheet – (Test OK).
- Test changement des valeurs – (test Not Ok). Le problème se résumait à une erreur de code sur la mise à jour des cellules du tableau Iypsheet.
c.d.f.d