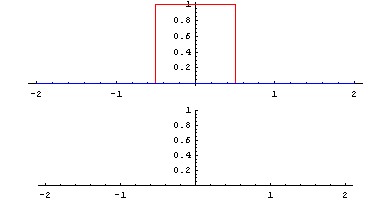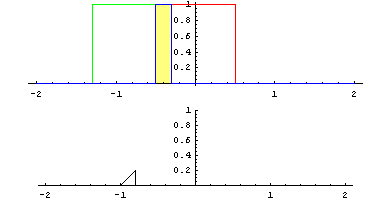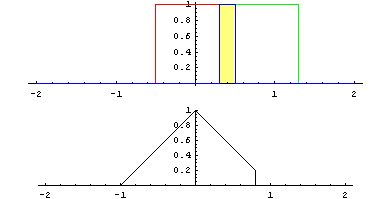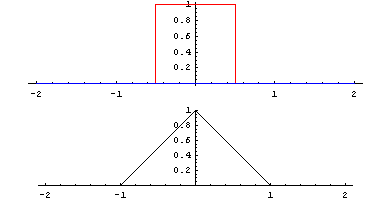
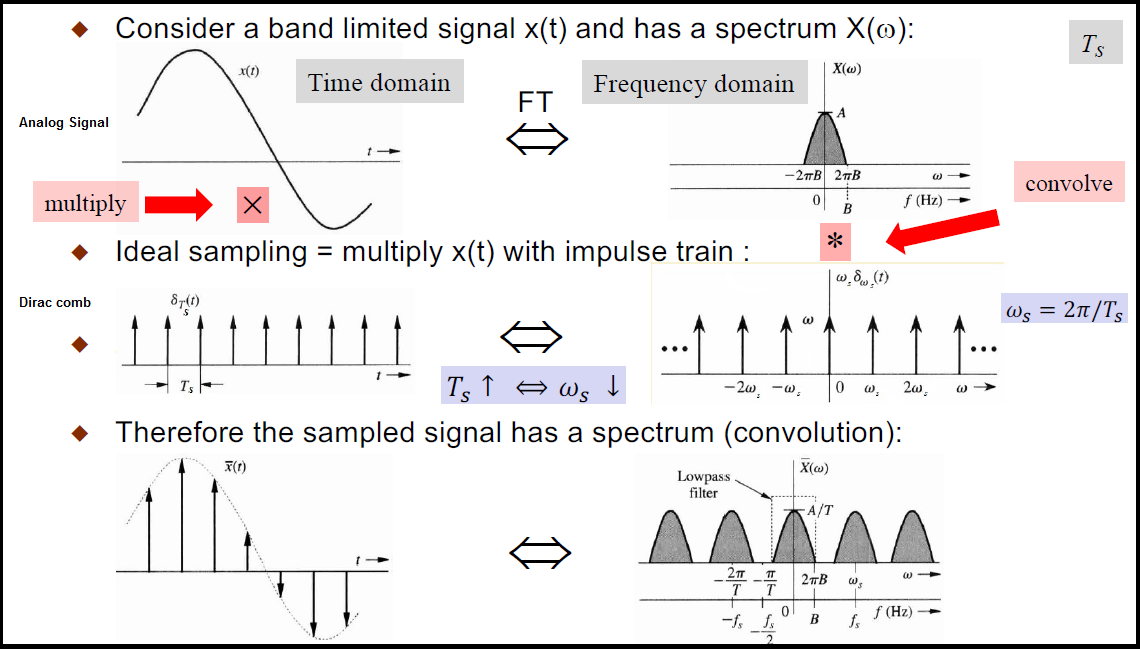
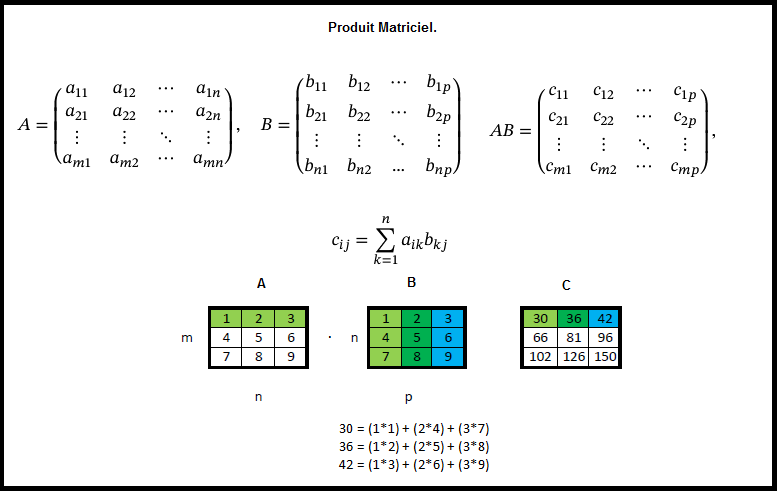
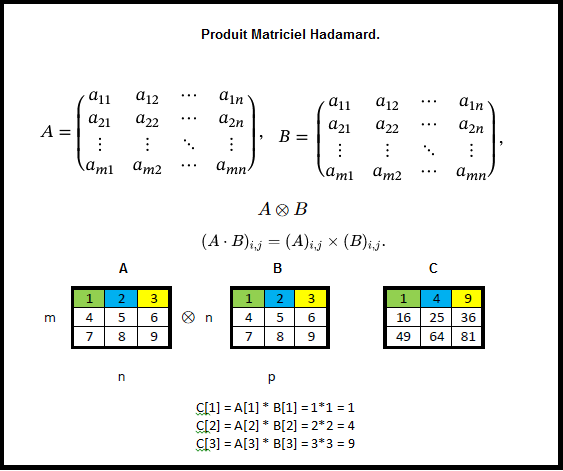
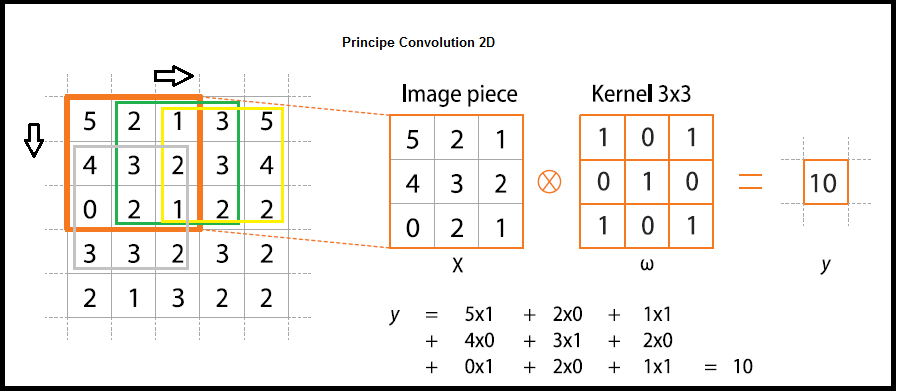
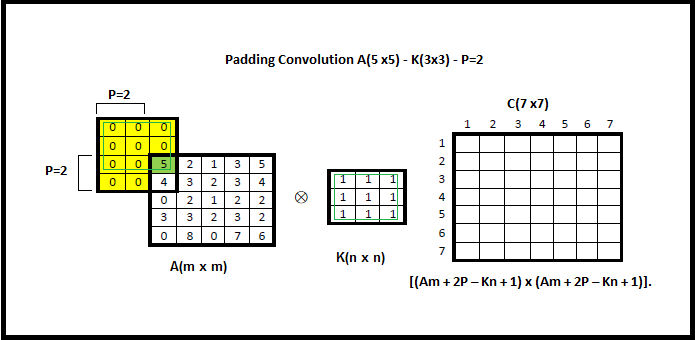
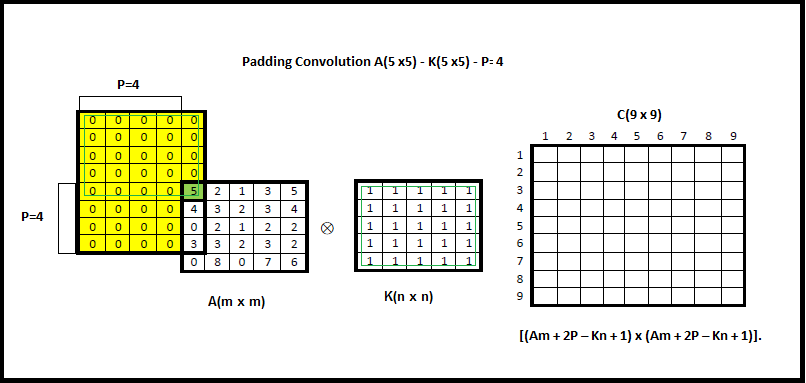
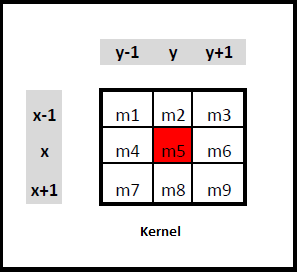
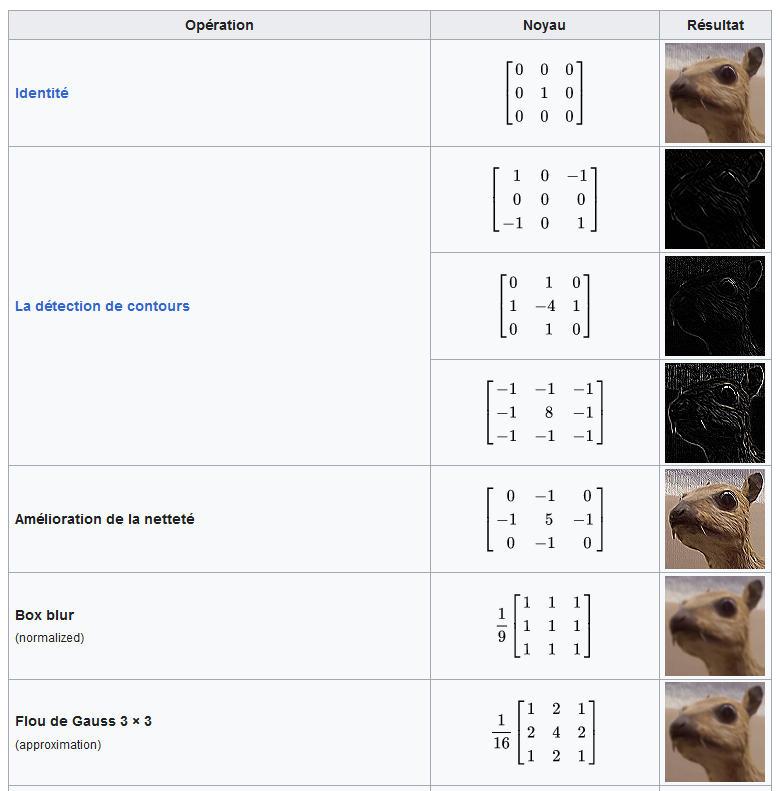
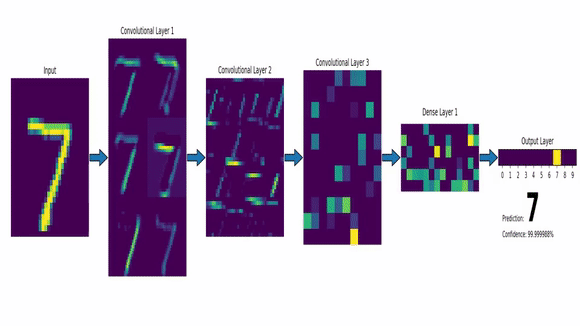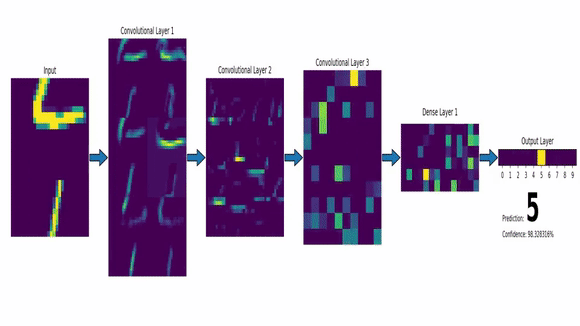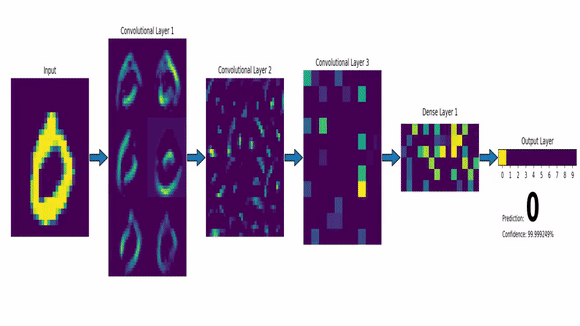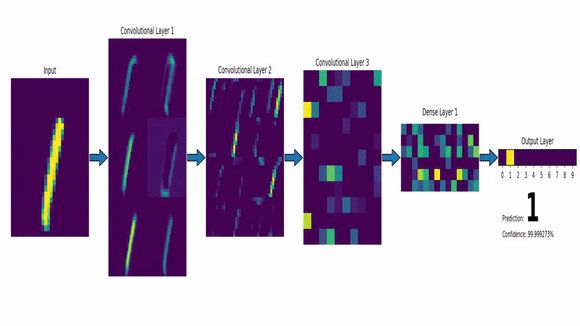
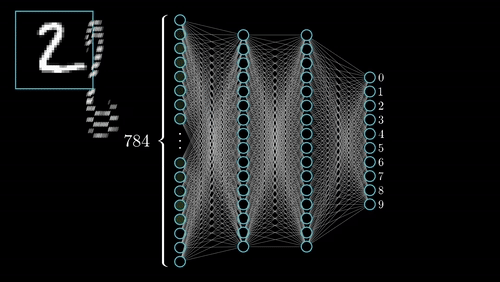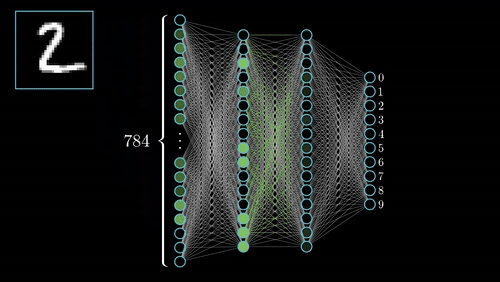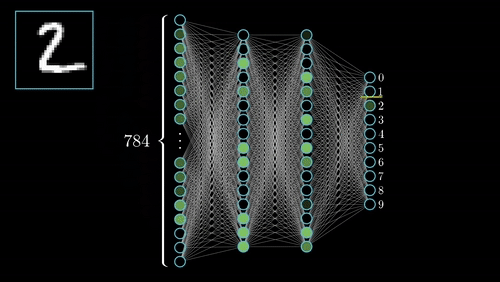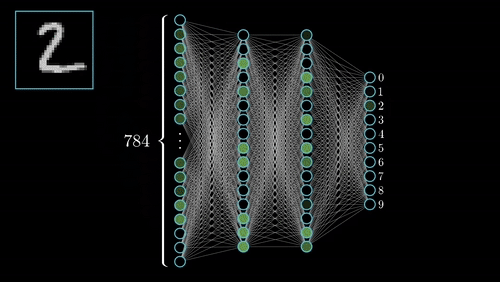
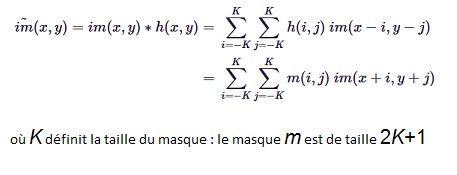Identité – dentity : Kernel (3×3) = ([[0,0,0],[0,1,0],[0,0,0]])
Edge detection – Détection de contours : Kernel (3×3) = ([[0,1,0],[1,-4,1],[0,1,0]])
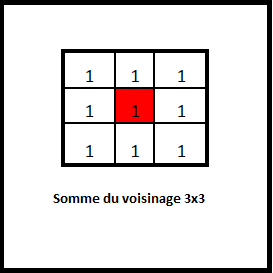
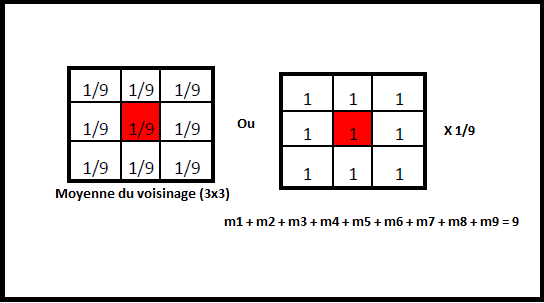
Box Blur – moyenner : Kernel (3×3) = ([[1,1,1],[1,1,1],[1,1,1]]) * (1/9)
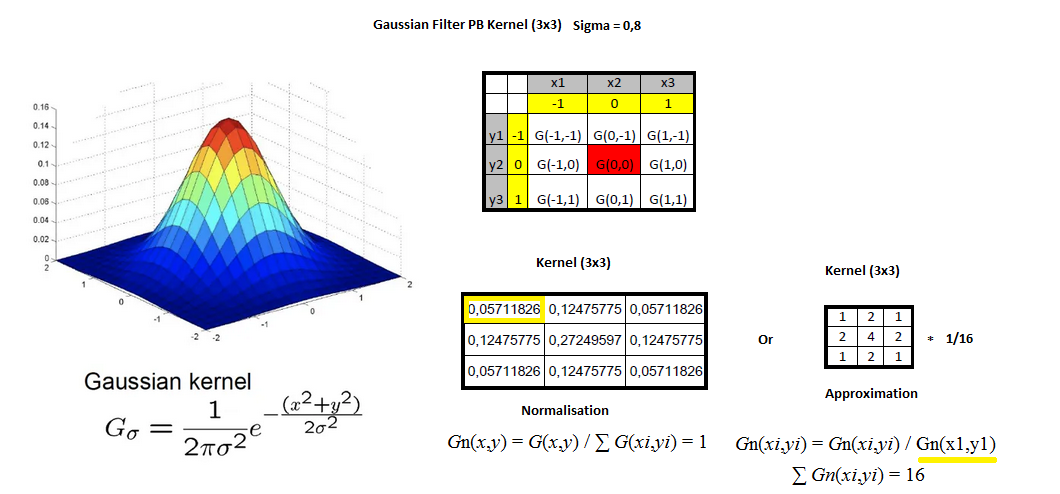
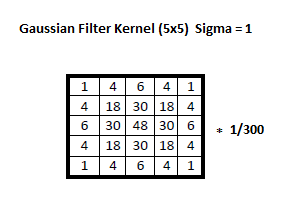
Gaussian Blur – Flouttage : Kernel (3×3) = ([[1,2,1],[2,4,2],[1,2,1]]) * (1/16)
Edge Reinforcement – Renforcement de bords : Kernel (3×3) = ([[0,0,0],[-1,1,0],[0,0,0]])
Pushback – Repoussage : Kernel (3×3) = ([[-2,-1,0],[-1,1,1],[0,1,2]])
Sharpen – Augmentation de Contraste : Kernel (3×3) = ([[0,-1,0],[-1,5,-1],[0,-1,0]])
Sharpen – Augmentation de Contraste : Kernel (5×5) = ([[0,0,0,0,0],[0,0,-1,0,0],[0,-1,5,-1,0],[0,0,-1,0,0],[0,0,0,0,0]])
Et bien d’autres plus toutes les variantes.
Rem : il existe d’autres filtres non Convolutif comme par exemple le filtre Median (filtre statistique non linéaire) qui utilise le principe de fenêtre glissante sur le signal comme un filtre de convolution.