Réseau de neurone supervisé - Data Set - MNIST Fashion
Data Set MNIST Fashion

Fashion MNIST est un jeu de données de qui contient 70 000 images en niveaux de gris répartie sur 1 des 10 catégories. Les images montrent des vêtements, d'articles de Zalando , en basse résolution (28 x 28 pixels). La base de données est repartie en un ensemble de 60.000 exemples de Training et d'un ensemble de 10.000 exemples de test Cette base de données vise à remplacer le jeu de données MNIST (de chiffres écrit à la main) qui n’était plus assez complexe dans une logique d'apprentissage automatique.
Bien que l'ensemble de données soit relativement simple, il peut être utilisé comme base pour apprendre, pratiquer, développer, évaluer et utiliser des réseaux de neurones supervisé profond pour la classification d'images à partir de zéro. Cela comprend comment développer un faisceau de test robuste pour estimer les performances du modèle, comment explorer les améliorations du modèle et comment enregistrer le modèle et le charger plus tard pour faire des prédictions sur de nouvelles données.
Réseau Neuronique Supervisé Dense
Ce modèle de réseau supervisé est certainement le premier modèle qui a été utilisé en vue de la classification d’images. Il est constitué de plusieurs couches. Une couche d’entrée, deux couches cachées (Hiden) et d’une couche de sortie.
Modèle du réseau.
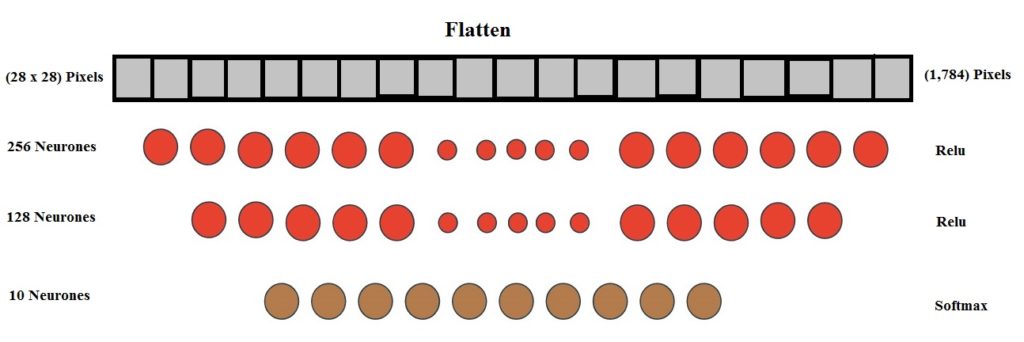
Couche d’entrée.
La particularité de la couche d’entrée est que cette couche est appelée Flatten. L’image d’entrée étant constituée d’une matrice de (28x28) pixels, on étale celle-ci dans un seul vecteur soit (28x28 = 784). En résume la couche d’entrée est constituée de 784 neurones contenant chacun un pixel.
Les Couches cachées (Hiden) – Généralement de puissance 2
Les couches Hiden sont au nombre de deux. Une de 256 neurones et une de 128 neurones.
Couche de sortie.
La couche de sortie Softmax est constituée de 10 neurones. C’est 10 neurones correspondent aux 10 classes (0 – 9) à détecter. La couche Softmax par définition mathématique n’autorise qu’un seul résulta correspondant à la probabilité maximum d’une des classe. Dans ce réseau, un pantalon ne peut pas être à la foi un pantalon et un sac….
Limitation lors de l'exécution du code.
Pour exécution du code, comme la partie Training & Evaluate peuvent prendre énormément de temps en fonction du modèle et de la puissance de calcul disponible, ces phases ne seront pas exécutées Online. J’ai réalisé au préalable le trainging et j’affiche uniquement les résultats. Seul la partie prédiction à partir du modèle sera exécuté Online.
Conclusion.
Comme précisé en intro, ce modèle est juste une base de travail. Le modèle évalué n’atteint qu’un Accuracy de 88.22% et un Loss de 32,54%. Ce modèle n’est pas exploitable en l’état. Bien qu’il pourrait être amélioré, ce type de modèle pour la classification d’images n’est plus utilisé et est remplacé par un modèle CNN ( Convolutional Neural Network) ou (Réseaux Neuronal Convolutif).
Réseau Neuronique CNN - Convolutional Neural Network
Contrairement au réseau Dense ou l’image était injectée sous forme de vecteur (Couche Flatten), ici l’image est injectée sous forme matricielle dans une couche de Convolution. Je ne vais pas ici vous expliquer l’analyse d’mage par convolution. Je vous invite à regarder sur le Net les explications relatives à la convolution d’images dans le cadre du Deeplearning.
Modèle du réseau.
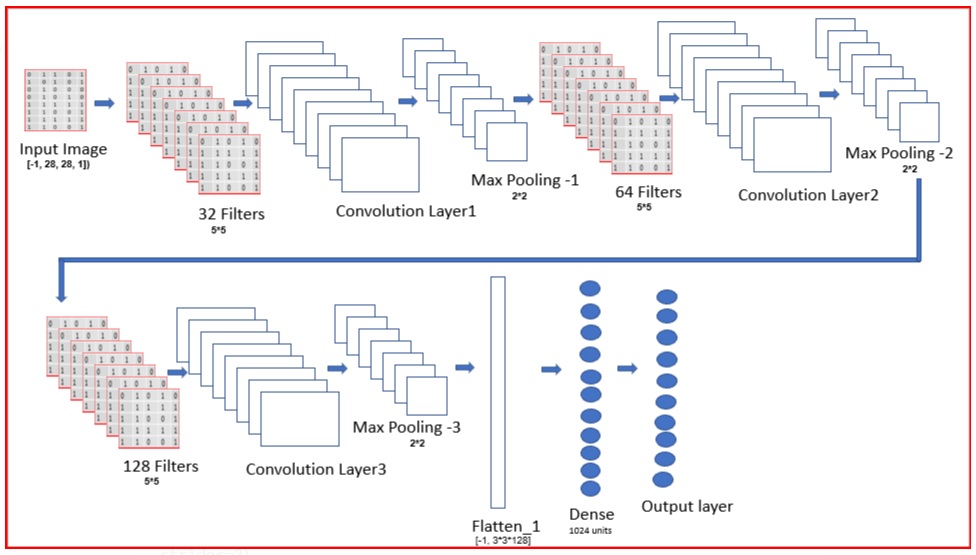
Le réseau est constitué d’une cascade de 3 layers de convolution, suivit par une couche Flatten, suivit par une couche Dense et pour finir d’une couche de sortie Softmax. Entre chaque couche de convolution on ajoute deux algorithmes. Un algorithme Max Pooling et un algorithme Dropout.
Max Pooling.
Le Max Pooling ou couche Max Pooling est un algorithme d’optimalisation du résultat de la couche de convolution. Il réduit la taille spatiale d'une image intermédiaire, réduisant ainsi la quantité de paramètres et de calcul dans le réseau pour la couche de convolution suivante.
Dropout.
Le Dropout ou couche Dropout est un algorithme d’optimalisation. Il a pour but la mise en vielle d’un ou de plusieurs neurone qui seraient inactif pendant le Training. Le résultat est l’accélération du calcul de la couche suivante. Ils seront automatiquement réactivés lors du Training suivant.
Méthodes Training & Evaluation.
Une méthode classique basée sur le nombre « Epochs » la taille de « Bachs » ainsi que le nombre de « Steps » d’évaluation.
La deuxième méthode, méthode « Metric » utilise une fonction Callback qui permet par exemple de sauvegarder après training le meilleur modèle avec un Loss minimum ou une Accuracy maximum (voir Doc Tensorflow).
Synthèse du Modèle.
Bien que ce modèle semble complexe, il est relativement simple. Il existe dans API Keras (voir FAQ) des modelés beaucoup plus complexes comme par exemple le modèle VGG-19 qui est constitué de 19 couches.
Limitation lors de l'exécution du code.
Pour exécution du code, comme la partie Training & Evaluate peuvent prendre énormément de temps en fonction du modèle et de la puissance de calcul disponible, ces phases ne seront pas exécutées Online. J’ai réalisé au préalable le trainging et j’affiche uniquement les résultats. Seul la partie prédiction à partir du modèle sera exécuté Online.
Conclusion.
Comme précisé en intro, ce modèle est juste une base de travail. Le modèle évalué n’atteint qu’un Accuracy de 92.36% et un Loss de 23,36%. Ce modèle n’est pas exploitable en l’état bien qu’il pourrait être amélioré.
Ce modèle n’a pour but que de décrire la structure fondamentale d’un réseau supervisé CNN de classification d’images. Dans l’application suivante (Classification d’images Dogs & Cats nous essaierons d’appliquer tous ces principes pour obtenir un modèle performent.
Mise en Production du Modèle CNN MNIST Fashion.
Après avoir créé, entrainé, évalué et sauvé un modèle, il reste le problème de sa mise en production. Il existe différentes manières pour la mise en production d’un modèle comme par exemple l’utilisation d’un Clound spécialisé ou d’un Hardware spécifique. Cela dépendra de la complexité du modèle et de son application (voir FAQ).
Pour ma part pour mes tests, j’ai opté pour une application Web. Pour la mise en œuvre de cette application, j’utilise Jupyter Notebbok qui est un serveur Local Web ainsi que l’API IpyWidgets qui permet d’écrire en Python une interface Web le tout sur un serveur Linux. Pour plus d’information (voir FAQ).
Procédure de l’application.
Chargement du Modèle.
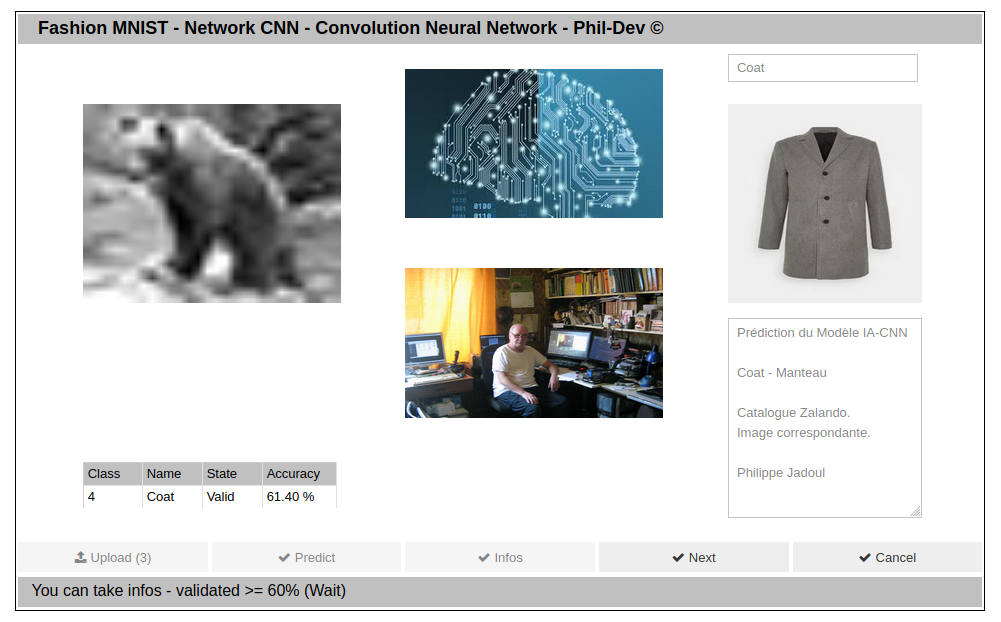
Bien que celui-ci ne soit pas optimun (Accuracy 92,36% - Loss 23,36%) il permettra de mettre en évidence le danger du Deeplearning d’un modèle ou du Training médiocre de celui-ci.
Test de l’image d’entrée.
L’image d’entée étant en niveau de gris (Convolution 2D) on teste le rapport des pixels Noir et Blanc. Une image avec 50% de noir ou de blanc sera rejetée.
Prédiction.
Si le résultat de la prédiction donne un résultat inférieur à 60%, la prédiction ne sera pas acceptée. Dans le cas où il est supérieure ou égal à 60%, le résultat de la prédiction est affichée (Bouton Infos) et une information est donné.
Screen de l'Application
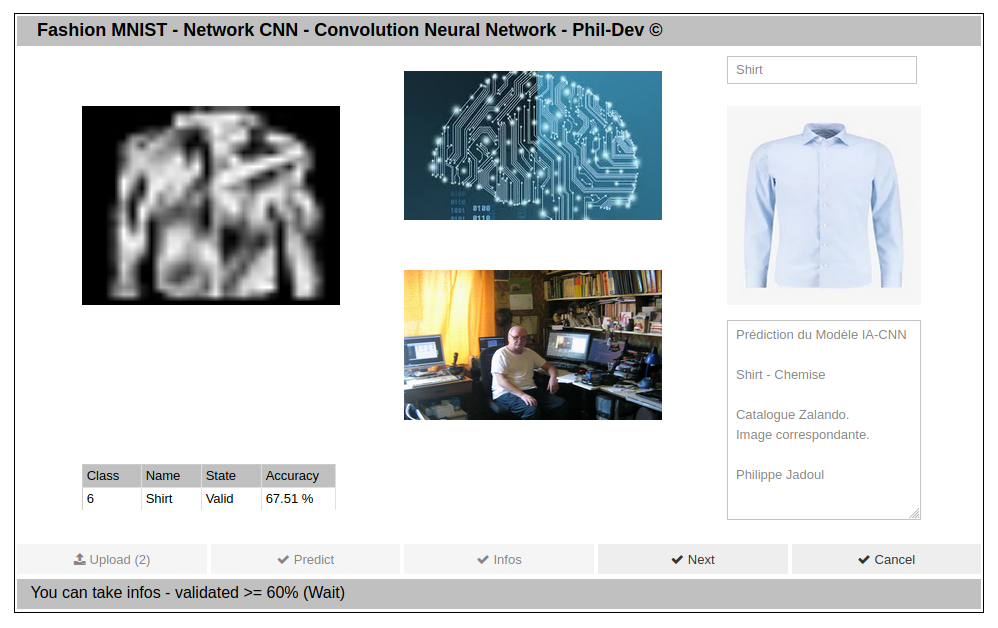
Limite du Modèle.